Готовые проекты компьютерное зрение. Как камеры следят за нами на улицах российских городов
Последние лет восемь я активно занимаюсь задачами, связанными с распознаванием образов, компьютерным зрением, машинным обучением. Получилось накопить достаточно большой багаж опыта и проектов (что-то своё, что-то в ранге штатного программиста, что-то под заказ). К тому же, с тех пор, как я написал пару статей на Хабре, со мной часто связываются читатели, просят помочь с их задачей, посоветовать что-то. Так что достаточно часто натыкаюсь на совершенно непредсказуемые применения CV алгоритмов.
Но, чёрт подери, в 90% случаев я вижу одну и ту же системную ошибку. Раз за разом. За последние лет 5 я её объяснял уже десяткам людей. Да что там, периодически и сам её совершаю…
В 99% задач компьютерного зрения то представление о задаче, которое вы сформулировали у себя в голове, а тем более тот путь решения, который вы наметили, не имеет с реальностью ничего общего. Всегда будут возникать ситуации, про которые вы даже не могли подумать. Единственный способ сформулировать задачу - набрать базу примеров и работать с ней, учитывая как идеальные, так и самые плохие ситуации. Чем шире база-тем точнее поставлена задача. Без базы говорить о задаче нельзя.
Тривиальная мысль. Но все ошибаются. Абсолютно все. В статье я приведу несколько примеров таких ситуаций. Когда задача поставлена плохо, когда хорошо. И какие подводные камни вас ждут в формировании ТЗ для систем компьютерного зрения.
Сама по себе задача, на мой взгляд, скорее решаема. Если брать отметки как опорные точки и сравнивать теми же методами, которыми сравнивают . Но, опять же, пока не протестируешь базу хотя бы на пару сотен примеров - никогда не узнаешь, можно ли работу успешно выполнить. Но почему-то такое предложение не понравилось автору статьи… Жаль!
Это два наиболее осмысленных и репрезентативных, на мой взгляд, примера. По ним можно понять, почему нужно абстрагироваться от идеи и смотреть реальные кадры.
Ещё несколько примеров, с которыми я встречался, но уже в двух словах. Во всех этих примерах у людей не было ни единой фотографии на момент, когда они начали спрашивать о реализуемости задачи:
1)
Распознавание номеров у марафонцев на футболках по видеопотоку (картинка из Яндыкса)
Хы
. Пока готовил статью натолкнулся на это . Очень хороший пример, на котором видны все потенциальные проблемы. Это и разные шрифты, это и нестабильный фон с тенями, это нерезкость и замятые углы. И самое главное. Заказчик предлагает идеализированную базу . Снятую на хороший фотоаппарат солнечным днём. Попробуйте посмотреть номера спортсменов на майках поискав поиском яндыкса.
Хы.Хы
За пару часов до публикации автор заказа внезапно вышел на меня сам с предложением взяться за работу, от которого я отказался:) Всё же это карма, добавить это в статью.
2)
Распознавание текста на фотографиях экранов телефонов
3)
И, мой любимый пример. Письмо на почту:
" нужна программа в коммерческий сектор для распознания избражений.
Алгоритм работы такой. оператор программы задает изображения предмета(-ов) в нескольких ракурсах и т.п.
потом при появленини этого или максимально похожего изображения предмета, програма совершает требуемое/заданное действие.
деталей естественно не могу пока рассказать.
" (орфография, пунктуация сохранены)
Хорошие
Но не всё так плохо! Ситуация, когда задача ставится идеально, встречается часто. Моя любимая: «Нужно ПО для автоматического подсчета лосей на фото.Пример фото с лосями высылаю.»


Оба фото кликабельны.
До сих пор жалею, что с этой задачей не срослось. Сначала кандидатскую защищал и был занят, а потом заказчик как-то энтузиазм потерял (или нашёл других исполнителей).
В постановке нет ни малейшей трактовки решения. Только две вещи: «что нужно сделать», «входные данные». Много входных данных. Всё.
Мысль - вывод
Единственный способ поставить задачу - набрать базу и определить методологию работы по этой базе. Что вы хотите получить? Какие границы применимости алгоритма? Без этого вы не только не сможете подойти к задаче, вы не сможете её сдать. Без базы данных заказчик всегда сможет сказать «У вас не работает такой-то случай. Но это же критичная ситуация! Без него я не приму работу».Как сформировать базу
Наверное, всё это был приквел к статье. Настоящая статья начинается тут. Идея того, что в любой задаче CV и ML нужна база для тестирования - очевидна. Но как набрать такую базу? На моей памяти три-четыре раза первая набранная база спускалась в унитаз. Иногда и вторая. Потому что была нерепрезентативна. В чём сложность?Нужно понимать, что «сбор базы» = «постановка задачи». Собранная база должна:
1. Отражать проблематику задачи;
2. Отражать условия, в которых будет решаться задача;
3. Формулировать задачу как таковую;
4. Приводить заказчика и исполнителя к консенсусу относительно того, что было сделано.
Время года
Пару лет назад мы с другом решили сделать систему, которая могла бы работать на мобильниках и распознавать автомобильные номера.. На тот момент мы были весьма умудрённые в CV системах. Знали, что нужно собирать такую базу, чтобы плохо было. Чтобы посмотрел на неё и сразу понял все проблемы. Мы собрали такую базу:



Сделали алгоритм, и он даже неплохо работал. Давал 80-85% распознавания выделенных номеров.
Ну да… Только летом, когда все номера стали чистые и хорошие точность системы просела процентов на 5…
Биометрия
Достаточно много в своей жизни мы работали с биометрией ( , ). И, кажется, наступили на все возможные грабли при сборе биометрических баз.База должна быть собрана в разных помещениях. Когда аппарат для сбора базы стоит только у разработчиков - рано или поздно выяснится, что он завязан на соседнюю лампу.
В биометрических базах нужно иметь 5-10 снимков для каждого человека. И эти 5-10 снимков должны быть сделаны в разные дни, в разное время дня. Подходя к биометрическому сканеру несколько раз подряд, человек сканируется одним и тем же способом. Подходя в разные дни - по-разному. Некоторые биометрические характеристики могут немножко меняться в течении суток.
База, собранная из разработчиков нерепрезентативна. Они подсознательно считываются так, чтобы всё сработало…
У вас новая модель сканера? А вы уверены, что он работает со старой базой?
Вот глаза собранные с разных сканеров. Разные поля работы, разные блики, разные тени, разные пространственные разрешения, и.т.д.






База для нейронных сетей и алгоритмов обучения
Если у вас в коде используется какой-то алгоритм обучения - пиши пропало. Вам нужно формировать базу для обучения с его учётом. Предположим, в вашей задаче распознавания имеется два сильно отличающихся шрифта. Первый встречается в 90% случаев, второй в 10%. Если вы нарежете эти два шрифта в данной пропорции и обучитесь по ним единым классификатором, то с высокой вероятностью буквы первого шрифта будут распознаваться, а буквы второго нет. Ибо нейронная сеть/SVM найдёт локальный минимум не там, где распознаётся 97% первого шрифта и 97% второго, а там где распознаётся 99% первого шрифта и 0% второго. В вашей базе должно быть достаточно примеров каждого шрифта, чтобы обучение не ушло в другой минимум.Как сформировать базу при работе с реальным заказчиком
Одна из нетривиальных проблем при сборе базы - кто это должен делать. Заказчик или исполнитель. Сначала приведу несколько печальных примеров из жизни.Я нанимаю вас, чтобы вы решили мне задачу!
Именно такую фразу я услышал однажды. И блин, не поспоришь. Но вот только базу нужно было бы собирать на заводе, куда бы нас никто не пустил. А уж тем более, не дал бы нам монтировать оборудование. Те данные, которые давал заказчик были бесполезны: объект размером в несколько пикселей, сильно зашумлённая камера с импульсными помехами, которая периодически дергается, от силы двадцать тестовых картинок. На предложения поставить более хорошую камеру, выбрать более хороший ракурс для съёмки, сделать базу хотя бы на пару сотен примеров, заказчик ответил фразой из заголовка.У нас нет времени этим заниматься!
Однажды директор весьма крупной компании (человек 100 штата + офисы во многих странах мира) предложил пообщаться. В продукте, который выпускала эта компания часть функционала была реализована очень старыми и очень простыми алгоритмами. Директор рассказал нам, что давно грезит о модификации данного функционала в современные алгоритмы. Даже нанимал две разных команды разработчиков. Но не срослось. Одна команда по его словам слишком теоретизировала, а вторая никакой теории не знала и тривиальщину делала. Мы решили попробовать.На следующий день нам выдали доступ к огромному массиву сырой информации. Сильно больше, чем я бы сумел просмотреть за год. Потратив на анализ информации пару дней мы насторожились спросили: «А что собственно вам нужно от новых алгоритмов?». Нам назвали десятка два ситуаций, когда текущие алгоритмы не работают. Но за пару дней я видел лишь одну-две указных ситуации. Просмотрев ещё пачку данных смог найти ещё одну. На вопрос: «какие ситуации беспокоят ваших клиентов в первую очередь?», - ни директор ни его главные инженеры не смогли дать ответа. У них не было такой статистики.
Мы исследовали вопрос и предложили алгоритм решения, который мог автоматически собрать все возможные ситуации. Но нам нужно было помочь с двумя вещами. Во-первых, развернуть обработку информации на серверах самой фирмы (у нас не было ни достаточной вычислительной мощности, ни достаточного канала к тому месту, где хранились сырые данные). На это бы ушла неделя работы администратора фирмы. А во-вторых, представитель фирмы должен был классифицировать собранную информацию по важности и по тому как её нужно обрабатывать (это ещё дня три). К этому моменту мы уже потратили две-три недели своего времени на анализ данных, изучение статей по тематике и написание программ для сбора информации (никакого договора подписано на этот момент не было, всё делали на добровольных началах).
На что нам было заявлено: «Мы не можем отвлекать на эту задачу никого. Разбирайтесь сами». На чём мы откланялись и удалились.
Заказчик даёт базу
Был и другой случай. На этот раз заказчик поменьше. А система, которой занимается заказчик разбросана по всей территории страны. Зато заказчик понимает, что мы базу не соберём. И из всех сил старается собрать базу. Собирает. Очень большую и разнообразную. И даже уверяет, что база репрезентативна. Начинаем работать. Почти доделываем алгоритм. Перед сдачей выясняется, что на собранной базе-то алгоритм работает. И условиям договора мы удовлетворяем. Но вот база-то была нерепрезентативной. В ней нет 2/3 ситуаций. А те ситуации, что есть - представлены непропорционально. И на реальных данных система работает сильно хуже.Вот и получается. Мы старались. Всё что обещали - сделали, хотя задача оказалась сильно сложнее, чем планировали. Заказчик старался. Потратил много времени на сбор базы.
Но итоговый результат - хреновый. Пришлось что-то придумывать на ходу, хоть как-то затыкать дырки…
Так кто должен сформировать базу?
Проблема в том, что очень часто задачи компьютерного зрения возникают в сложных системах. Системах, которые делались десятки лет многими людьми. И разобраться в такой системе часто сильно дольше, чем решить саму задачу. А заказчик хочет чтобы разработка началась уже завтра. И естественно, предложение заплатить за подготовку ТЗ и базы сумму в 2 раза больше стоимости задачи, увеличить сроки в 3 раза, дать допуск к своим системам и алгоритмам, выделить сотрудника, который всё покажет и расскажет, вызывает у него недоумение.На мой взгляд решение любой задачи компьютерного зрения требует постоянного диалога между заказчиком и исполнителем, а так же желания заказчика сформулировать задачу. Исполнитель не видит всех нюансов бизнеса заказчика, не знает систему изнутри. Я ни разу не видел чтобы подход: «вот вам деньги, завтра сделайте мне решение» сработал. Решение-то было. Но работало ли оно как нужно?
Сам я как огня пытаюсь шарахаться от таких контрактов. Работаю ли я сам, или в какой-то фирме, которая взяла заказ на разработку.
В целом ситуацию можно представить так: предположим, вы хотите устроить свою свадьбу. Вы можете:
Продумать и организовать всё самому от начала до конца. По сути данный вариант - «решать задачу самому».
Продумать всё от начала до конца. Написать все сценарии. И нанять исполнителей для каждой роли. Тамаду для того чтобы гости не скучали, ресторан, чтобы все приготовили и провели. Написать основную канву для тамады, меню для ресторана. Этот вариант - это диалог. Обеспечить данными исполнителя, расписать всё, что требуется.
Можно продумать большими блоками, не вникая в детали. Нанять тамаду, пусть делает, что делает. Не согласовывать меню ресторана. Заказать модельеру подбор платья, причёски, имиджа. Головной боли минимум, но когда начнутся конкурсы на раздевание, то можно понять что что-то было сделано не так. Далеко не факт, что сформулировав задачу в стиле «распознайте мне символ» исполнитель и заказчик поймут одно и то же.
А можно всё заказать свадебному агентству. Дорого, думать совсем не надо. Но вот, что получится - уже не знает никто. Вариант - «сделайте мне хорошо». Скорее всего, качество будет зависеть от стоимости. Но не обязательно
Есть ли задачи, где база не нужна
Есть. Во-первых, в задачах, где база - это слишком сложно. Например, разработка робота, который анализирует видео, и по нему принимает решения. Нужен какой-то тестовый стенд. Можно сделать базы на какие-то отдельные функции. Но сделать базу по полному циклу действий зачастую нельзя. Во-вторых, когда идёт исследовательская работа. Например, идёт разработка не только алгоритмов, но и устройства, которым будет набираться база. Каждый день новое устройство, новые параметры. Когда алгоритм меняется по три раза в день. В таких условиях база бесполезна. Можно создавать какие-то локальные базы, изменяющиеся каждый день. Но что-то глобальное неосмысленно.В-третьих, это задачи, где можно сделать модель. Моделирование это вообще очень большая и сложная тема. Если возможно сделать хорошую модель задёшево, то конечно нужно её делать. Хотите распознать текст, где есть только один шрифт - проще всего создать алгоритм моделирования (
Давайте вернемся в детство, и вспомним фантастику. Ну, хотя бы Звездные войны, где есть такой желтый человекообразый робот. Он каким-то волшебным образом ходит и ориентируется в пространстве. По сути, у этого робота есть «глаза» и он «видит» окружающее пространство. Но как компьютеры могут что-либо видеть? Когда мы смотрим на что-то, мы понимаем, что мы видим, для нас зрительная информация осмысленна. Но подключив к компьютеру видеокамеры, мы получим лишь набор нулей и единиц, которые он с этой видеокамеры будет считывать. Как компьютеру «понять», что он «видит»? Для ответа на этот вопрос создана такая научная дисциплина, как Computer Vision (Компьютерное зрение). По сути, Computer Vision — это наука о том, как создать алгоритмы, которые анализируют изображения и ищут в них полезную информацию (информацию, которая необходима роботу для ориентации по данным, поступающим с видеокамеры). Задача компьютерного зрения является, по сути, задачей .
Существует несколько направлений и подходов в Computer Vision:
- Предобработка изображений.
- Сегментация.
- Выделение контуров.
- Нахождение особых точек.
- Нахождение объектов на изображении.
- Распознавание образов.
Разберем их более подробно.
Предобработка изображений. Как правило, перед тем как анализировать изображение, необходимо провести предварительную обработку, которая облегчит анализ. Например, удалить шумы, либо какие-то мелкие незначительные детали, которые мешают анализу, либо провести еще какую-либо обработку, которая облегчит анализ. В частности, для подавления шумов и мелких деталей используют фильтр размытия изображения.
Пример, зашумленное изображение:
После применения размытия по гауссу

Однако у него есть существенный недостаток: вместе с подавлением шумов размываются границы между областями изображение, а мелкие детали не исчезают, они просто превращаться в пятна. Для устранения данных недостатков используют медианную фильтрацию. Она хорошо справляется с импульсным шумом и удалением мелких деталей, причем, границы не размываются. Однако медианная фильтрация не справятся с гауссовым шумом.
Сегментация. Сегментация — это разделение изображение на области. Например, одна область — фон, другая конкретный объект. Или, например, есть у нас фотография, где морской пляж. Мы делим ее на области: море, пляж, небо. Для чего нужна сегментация? Ну например, у нас есть задача найти на изображении объект. Для ускорения мы ограничиваем область поиска определенным сегментом, если точно знаем, что объект может быть только в этой области. Или, например, в геоинформатике может быть задача сегментации спутниковых или аэро фотоснимков.
Пример. Вот у нас исходное изображение:

А вот его сегментация:

В данном случае при сегментации использовались текстурные признаки.
Выделение контуров. Для чего на изображении выделять контур? Давайте предположим, что нам надо решить задачу поиска на фотографии лица человека. Допустим, мы сначала попытались решить эту задачу «в лоб» — тупым перебором. Берем «квадратик» с изображением лица и попиксельно сравниваем его с изображением, перемещая квадратик попиксельно слева направо и так по каждой строке пикселей. Понятно, что так будет работать слишком долго, к тому-же, такой алгоритм найдет не любое лицо, а только одно конкретное. И то, если его чуть-чуть повернуть или изменить масштаб, то все, поиск перестанет работать. Другое дело, если у нас есть контур изображения и контур лица. Мы сможем линии контура описать каким-то иным способом, кроме растровой картинки, например, в виде списка координат его точек, в виде группы линий, описанных разными математическими формулами. Короче говоря, выделим контур, мы можем его векторизовать и производить уже не поиск растра среди растра, а векторного объекта среди векторных объектов. Это гораздо быстрее, кроме того, тогда описание объектов может быть инвариантным к поворотам и/или масштабу (то есть, мы можем находить объекты даже если они повернуты или масштабированы).
Теперь возникает вопрос: а как выделить контур? Как правило, сначала получают так называемый контурный препарат, чаще всего это градиент (скорость изменения яркости). То есть, получив градиент изображения, мы увидим белыми те области, где у нас резкие перепады яркости, и черными где яркость меняется плавно или вообще не меняется. Иными словами, все границы у нас будут выделены белыми полосами. Дальше эти белые полосы мы сужаем и получаем контур (если описать кратко что делает алгоритм получения контура). В настоящее время существует ряд стандартных алгоритмов выделения контура, например, алгоритм Кэнни, который реализован в библиотеке OpenCV.
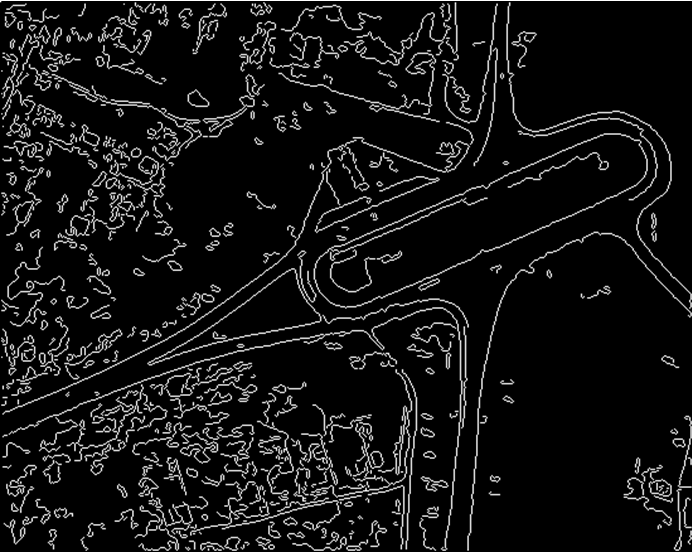
Пример выделения контуров.
Исходное изображение:

Выделенные контуры:
Нахождение особых точек. Другой метод анализа изображения — это нахождение на нем особых точек. В качестве особых точек могут быть, например, углы, экстремумы яркости, а также другие особенности изображения. С особыми точками можно делать примерно тоже, что и с контурами — описать в векторном виде. Например, можно описать взаимное расположение точек в виде расстояний между точками. При повороте объектов расстояние не меняется — значит, такое описание будет инвариантно к повороту. А чтобы сделать модель еще и инвариантной к масштабу, можно описать не расстояние, а отношения между расстояниями — действительно, если расстояние одной пары точек в два раза больше чем другой пары точек, о оно будет всегда в два раза больше, независимо от того, во сколько раз мы увеличили или уменьшили объект. В настоящее время существует много типовых алгоритмов нахождения особых точек, например, детектор Харриса, Моравеца, MSER, AKAZE и так далее. Многие из существующих алгоритмов нахождения особых точек реализованы в OpenCV.
Распознавание образов. Данный процесс происходит когда изображение проанализировано, на нем выделены контуры и преобразованы в векторный вид, либо найден особые точки и вычислено их взаимное расположение (либо и то и другое вместе). В общем, получена совокупность признаков, по которым и происходит определение, какие на картинке есть объекты. Для этого исполняться различные эвристические алгоритмы, например, . Вообще, как распознавать образы — это целая наука, называемая Теория распознавания образов.
Распознавание образов - это отнесение исходных данных к определенному классу с помощью выделения существенных признаков, характеризующих эти данные, из общей массы несущественных данных. При постановке задач распознавания стараются пользоваться математическим языком, стремясь — в отличие от теории искусственных нейронных сетей, где основой является получение результата путём эксперимента, — заменить эксперимент логическими рассуждениями и математическими доказательствами. Классическая постановка задачи распознавания образов: Дано множество объектов. Относительно них необходимо провести классификацию. Множество представлено подмножествами, которые называются классами. Заданы: информация о классах, описание всего множества и описание информации об объекте, принадлежность которого к определенному классу неизвестна. Требуется по имеющейся информации о классах и описании объекта установить — к какому классу относится этот объект.
Существует несколько подходов к распознаванию образов:
- Перечисление. Каждый класс задаётся путём прямого указания его членов. Такой подход используется в том случае, если доступна полная априорная информация о всех возможных объектах распознавания. Предъявляемые системе образы сравниваются с заданными описаниями представителей классов и относятся к тому классу, которому принадлежат наиболее сходные с ними образцы. Такой подход называют методом сравнения с эталоном. Он, к примеру, применим при распознавании машинопечатных символов определённого шрифта. Его недостатком является слабая устойчивость к шумам и искажениям в распознаваемых образах.
- Задание общих свойств . Класс задаётся указанием некоторых признаков, присущих всем его членам. Распознаваемый объект в таком случае не сравнивается напрямую с группой эталонных объектов. В его первичном описании выделяются значения определённого набора признаков, которые затем сравниваются с заданными признаками классов. Такой подход называется сопоставлением по признакам. Он экономичнее метода сравнения с эталоном в вопросе количества памяти, необходимой для хранения описаний классов. Кроме того, он допускает некоторую вариативность распознаваемых образов. Однако, главной сложностью является определение полного набора признаков, точно отличающих членов одного класса от членов всех остальных.
- Кластеризация. В случае, когда объекты описываются векторами признаков или измерений, класс можно рассматривать как кластер. Распознавание осуществляется на основе расчёта расстояния (чаще всего это евклидово расстояние) описания объекта до каждого из имеющихся кластеров. Если кластеры достаточно разнесены в пространстве, при распознавании хорошо работает метод оценки расстояний от рассматриваемого объекта до каждого из кластеров. Сложность распознавания возрастает, если кластеры перекрываются. Обычно это является следствием недостаточности исходной информации и может быть разрешено увеличением количества измерений объектов. Для задания исходных кластеров целесообразно использовать процедуру обучения.
Для того, чтобы провести процедуру распознавание образов, объекты нужно как-то описать. Существует также несколько способов описания объектов:
- Евклидово пространство — объекты представляются точками в евклидовом пространстве их вычисленных параметров, представление в виде набора измерений;
- Списки признаков — выявление качественных характеристик объекта и построение характеризующего вектора;
- Структурное описание — выявление структурных элементов объекта и определение их взаимосвязи.
Нахождение объектов на изображении. Задача нахождения объектов на изображении сводиться к тому, что нам необходимо найти заранее известный объект, например, лицо человека. Для этого данный объект мы описываем какими-либо признаками, и ищем на изображением объект, удовлетворяющий этим признакам. Эта задача похожа на задачу распознавания образов, но с тем лишь отличием, что тут надо не классифицировать неизвестный объект, а найти где на изображении находиться известный объект с заданными признаками. Часто к задаче нахождения объектов на изображениях предъявляют требования по быстродействию, так как это необходимо делать в режиме реального времени.
Классический пример подобных алгоритмов — распознавание лиц по методу Виола Джонсона. Хотя этот метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом, он до сих пор является основополагающим для поиска объектов на изображении в реальном времени. Основные принципы, на которых основан метод, таковы:
- Используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты;
- Используются признаки Хаара, с помощью которых происходит поиск нужного объекта (в данном контексте, лица и его черт);
- Используется бустинг (от англ. boost – улучшение, усиление) для выбора наиболее подходящих признаков для искомого объекта на данной части изображения;
- Все признаки поступают на вход классификатора, который даёт результат «верно» либо «ложь»;
- Используются каскады признаков для быстрого отбрасывания окон, где не найдено лицо.
Скажу пару слов об интегральном изображении. Дело в том, что в задачах компьютерного зрения часто приходиться использовать метод сканирующего окна: мы двигаем окно попиксельно по всему изображению и для каждого пикселя окна выполняем определенный алгоритм. Как я уже говорил в начале статьи, такой подход работает медленно, особенно если размер скользящего окна и изображения большой. Например, если у нас размер изображения 1000 на 1000 то это будет миллион пикселей. А если скользящее окно 10 на 10 в нем 100 пикселей и алгоритм, обрабатывающий сто пикселей надо выполнить миллион раз. При получении интегрального изображения мы пробегам по картинке 1 раз и получаем матрицу, в которой каждый пиксель — это сумма яркостей прямоугольника, ограниченного этим пикселем и началом координат. Благодаря такой матрице, мы можем вычислить всего за 4 операции может вычислить сумму яркостей любого прямоугольника (хоть 10 на 10, хоть 30 на 30, хоть 100 на 50). Как правило, во многих случаях, обработка в скользящем окне как раз сводиться к вычислению суммы яркостей.
Как научить компьютер понимать, что изображено на картинке или фотографии? Нам это кажется просто, но для компьютера это всего лишь матрица, состоящая из нулей и единиц, из которой нужно извлечь важную информацию.
Что такое компьютерное зрение? Это способность компьютера «видеть»
Зрение — это важный источник информации для человека, с помощью него мы получаем, по разным данным, от 70 до 90% всей информации. И, естественно, если мы хотим создать умную машину, нам необходимо реализовать те же навыки и в компьютере.
Задача компьютерного зрения может быть сформулирована достаточно нечетко. Что такое «видеть»? Это понимать, что где расположено, просто глядя. В этом и заключены различия компьютерного зрения и зрения человека. Зрение для нас - это о мире, а также источник метрической информации - то есть способность понимать расстояния и размеры.
Семантическое ядро изображения
Глядя на изображение, мы можем охарактеризовать его по ряду признаков, так сказать, извлечь семантическую информацию.

Например, глядя на эту фотографию, мы можем сказать, что это вне помещения. Что это город, уличное движение. Что здесь есть автомобили. По конфигурации здания и по иероглифам мы можем догадаться, что это Юго-Восточная Азия. По портрету Мао Цзэдуна понимаем, что это Пекин, а если кто видел видеотрансляции или сам там побывал, сможет догадаться, что это знаменитая площадь Тяньаньмэнь.
Что мы можем ещё сказать о картинке, рассматривая её? Можем выделить объекты на изображении, сказать, вот там люди, здесь ближе - ограда. Вот зонтики, вот здание, вот плакаты. Это примеры классов очень важных объектов, поиском которых занимаются на данный момент.
Ещё мы можем извлечь некоторые признаки или атрибуты объектов. Например, здесь мы можем определить, что это не портрет какого-то рядового китайца, а именно Мао Цзэдуна.
По автомобилю можно определить, что это движущийся объект, и он жесткий, то есть во время движения не деформируется. Про флаги можно сказать, что это объекты, они также двигаются, но они не жесткие, постоянно деформируются. А также в сцене присутствует ветер, это можно определить по развивающемуся флагу, и даже можно определить направление ветра, например, он дует слева направо.
Значение расстояний и длин в компьютерном зрении
Очень важной является метрическая информация в науке про компьютерное зрение.Это всевозможные расстояния. Например, для марсохода это особенно важно, потому что команды с Земли идут порядка 20 минут и ответ столько же. Соответственно, связь туда-обратно - 40 минут. И если мы будем составлять план движения по командам Земли, то нужно это учитывать.

Удачно технологии компьютерного зрения интегрированы в видеоиграх. По видео можно построить трёхмерные модели объектов, людей, а по пользовательским фотографиям можно восстановить трёхмерные модели городов. А затем гулять по ним.
Компьютерное зрение- это достаточно широкая область. Она тесно переплетается с разными другими науками. Частично компьютерное зрениезахватывает область и иногда выделяет область машинного зрения, исторически так сложилось.
Анализ, распознавание образов - путь к созданию высшего разума
Разберем эти понятия отдельно.

Обработка изображений - это область алгоритмов, в которых на входе и на выходе - изображение, и мы уже с ним что-то делаем.
Анализ изображения - это область компьютерного зрения, которое фокусируется на работе с двухмерным изображением и делает из этого выводы.
Распознавание образов - это абстрактная математическая дисциплина, которая распознаёт данные в виде векторов. То есть на входе - вектор и нам что-то с ним нужно делать. Откуда этот вектор, нам не так уж принципиально знать.
Компьютерное зрение - это изначально было восстановление структуры из двухмерных изображений. Сейчас эта область стала более широкой и её можно трактовать вообще как принятие решений о физических объектах, основываясь на изображении. То есть искусственного интеллекта.
Параллельно с компьютерным зрением совершенно в другой области, в геодезии, развивалась фотограмметрия — это измерение расстояний между объектами по двухмерным изображениям.
Роботы могут «видеть»
И последнее - это машинное зрение. Под машинным зрением подразумевается зрение роботов. То есть решение некоторых производственных задач. Можно сказать, что компьютерное зрение - это одна большая наука. Она объединяет в себе некоторые другие науки частично. А когда компьютерное зрение получает какое-то конкретное приложение, то оно превращается в машинное зрение.

Область компьютерного зрения имеет массу практических применений. Оно связано с автоматизацией производства. На предприятиях эффективнее становится заменять ручной труд машинным. Машина не устаёт, не спит, у неё ненормированный рабочий график, она готова работать 365 дней в году. А значит, используя машинный труд, мы можем получить гарантированный результат в определённое время, и это достаточно интересно. Все задачи для систем компьютерного зрения имеют наглядное применение. И нет ничего лучше, чем увидеть результат сразу по картинке, только на стадии расчётов.
На пороге в мир искусственного интеллекта
Плюс области - это сложно! Существенная часть мозга отвечает за зрение и считается, что если научить компьютер «видеть», то есть в полной мере применить компьютерное зрение, то это одна из полных задач искусственного интеллекта. Если мы сможем решить проблему на уровне человека, скорее всего, одновременно мы решим задачу ИИ. Что очень хорошо! Или не очень хорошо, если смотреть «Терминатор 2».
Почему зрение — это сложно? Потому что изображение одних и тех же объектов может сильно разниться в зависимости от внешних факторов. В зависимости от точек наблюдения объекты выглядят по-разному.
К примеру, одна и та же фигура, снятая с разных ракурсов. И что самое интересное, у фигуры может быть один глаз, два глаза или полтора. А в зависимости от контекста (если это фото человека в футболке с нарисованными глазами), то глаз может быть и больше двух.
Компьютер ещё не понимает, но уже «видит»
Ещё один фактор, создающий сложности - это освещение. Одна и та же сцена с разным освещением будет выглядеть по-разному. Размер объектов может варьироваться. Причем объектов любых классов. Ну как можно сказать о человеке, что его рост 2 метра? Никак. Рост человека может составлять и 2.3 м, и 80 см. Как и объектов других типов, тем не менее это объекты одного и того же класса.

Особенно живые объекты претерпевают самые разнообразные деформации. Волосы людей, спортсмены, животные. Посмотрите снимки бегущих лошадей, определить, что происходит с их гривой и хвостом просто невозможно. А перекрытие объектов на изображении? Если подсунуть такую картинку компьютеру, то даже самая мощная машина затруднится выдать правильное решение.

Следующий вид — это маскировка. Некоторые объекты, животные маскируются под окружающую среду, причем достаточно умело. И пятна такие же и расцветка. Но тем не менее мы их видим, хотя не всегда издалека.
Ещё одна проблема - это движение. Объекты в движении претерпевают невообразимые деформации.
Многие объекты очень изменчивы. Вот, к примеру, на двух фото ниже объекты типа "кресло".

И на этом можно сидеть. Но научить машину, что такие разные вещи по форме, цвету, материалу все являются объектом "кресло" - очень сложно. В этом и состоит задача. Интегрировать методы компьютерного зрения - это научить машину понимать, анализировать, предполагать.

Интеграция компьютерного зрения в различные платформы
В массы компьютерное зрение начало проникать ещё в 2001 году, когда создали первые детекторы лиц. Сделали это два автора: Viola, Jones. Это был первый быстрый и достаточно надёжный алгоритм, который продемонстрировал мощь методов машинного обучения.
Сейчас у компьютерного зрения есть достаточно новое практическое применение - распознавание человека по лицу.

Но распознавать человека, как показывают в фильмах - в произвольных ракурсах, с разными условиями освещения - невозможно. Но решить задачу, один это или разные люди с разным освещением или в разной позе, похожие, как на фотографии в паспорте, можно с высокой степенью уверенности.
Требования к паспортным фотографиям во многом обусловлены особенностью алгоритмов распознавания по лицу.
К примеру, если у вас есть биометрический паспорт, то в некоторых современных аэропортах вы можете воспользоваться автоматической системой паспортного контроля.
компьютерного зрения - это способность распознавать произвольный текст
Возможно, кто-то пользовался системой распознавания текста. Одна из таких - это Fine Reader, очень популярная в Рунете система. Есть много форм, где нужно заполнять данные, они прекрасно сканируются, информация распознаётся системой очень хорошо. А вот с произвольным текстом на изображении дело обстоит гораздо хуже. Эта задача пока остаётся нерешенной.
Игры с участием компьютерного зрения, захват движения
Отдельная большая область — это создание трёхмерных моделей и захват движения (который довольно успешно реализован в компьютерных играх). Первая программа, компьютерное зрение использующая, — система взаимодействия с компьютером при помощи жестов. При ее создании было много чего открыто.
Сам алгоритм устроен довольно просто, но для его настройки потребовалось создать генератор искусственных изображений людей, чтобы получить миллион картинок. Суперкомпьютер с их помощью подобрал параметры алгоритма, по которым он теперь работает наилучшим образом.
Вот так миллион изображений и неделя счётного времени суперкомпьютера позволили создать алгоритм, который потребляет 12% мощности одного процессора и позволяет воспринимать позу человека в реальном времени. Это система Microsoft Kinect (2010 год).

Поиск изображений по содержанию позволяет загружать фотографию в систему, и по результатам она выдаст все снимки с таким же содержанием и сделанные с того же ракурса.
Примеры компьютерного зрения: трёхмерные и двухмерные карты сейчас делаются с его помощью. Карты для навигаторов автомобилей регулярно обновляются по данным с видеорегистраторов.
Существует база с миллиардами фотографий с геометками. Загружая снимок в эту базу, можно определить, где он был сделан и даже с какого ракурса. Естественно, при условии, что место достаточно популярное, что в своё время там побывали туристы и сделали ряд фотографий местности.
Роботы повсюду
Робототехника в нынешнее время повсюду, без неё никак. Сейчас существуют автомобили, в которых есть специальные камеры, распознающие пешеходов и дорожные знаки, чтобы передавать команды водителю (такая в некотором смысле компьютерная программа для зрения, помогающая автолюбителю). И есть полностью автоматизированные роботы-автомобили, но они не могут полагаться только на систему видеокамер без использования большого количества дополнительной информации.
Современный фотоаппарат — это аналог камеры-обскура
Поговорим про цифровое изображение. Современные цифровые камеры устроены по принципу камеры-обскуры. Только вместо отверстия, через которое проникает луч света и проецирует на задней стенке камеры контур предмета, у нас имеется специальная оптическая система под названием объектив. Задачей ее является собрать большой пучок света и преобразовать его таким образом, чтобы все лучи проходили через одну виртуальную точку с целью получить проекцию и сформировать изображение на плёнке или матрице.

Современные цифровые фотоаппараты (матрица) состоят из отдельных элементов - пикселей. Каждый пиксель позволяет измерять энергию света, который падает на этот пиксель суммарно, и на выходе выдавать одно число. Поэтому в цифровой камере мы получаем вместо изображения набор измерений яркости света, попавшего в отдельный пиксель — компьютерные Поэтому при увеличении изображения мы видим не плавные линии и четкие контуры, а сетку из окрашенных в различные тона квадратиков - пикселей.
Ниже вы видите первое цифровое изображение в мире.

Но что на этом изображении отсутствует? Цвет. А что такое цвет?
Психологическое восприятие цвета
Цвет - это то, что мы видим. Цвет объекта, одного и того же предмета для человека и кошки будет разным. Так как у нас (у людей) и у животных оптическая система - зрение, отличается. Поэтому цвет - это психологическое свойство нашего зрения, возникающее при наблюдении объектов и света. А не физическое свойство объекта и света. Цвет - это результат взаимодействия компонентов света, сцены и нашей зрительной системы.

Программирование компьютерного зрения на Python с помощью библиотек
Если вы решили всерьёз заняться изучением компьютерного зрения, стоит сразу приготовиться к ряду трудностей, наука эта не самая лёгкая и прячет в себе ряд подводных камней. Но "Программирование компьютерного зрения на Python" в авторстве Яна Эрика Солема - это книга, в которой все излагается максимально простым языком. Здесь вы познакомитесь с методами распознавания различных объектов в 3D, научитесь работать со стереоизображениями, виртуальной реальностью и многими другими приложениями компьютерного зрения. В книге достаточно примеров на языке Python. Но пояснения представлены, так сказать, обобщённо, дабы не перегрузить слишком научной и тяжелой информацией. Труд подойдёт студентам, просто любителям и энтузиастам. Скачать эту книгу и другие про компьютерное зрение (pdf-формата) можно в сети.
На данный момент существуют открытая библиотека алгоритмов компьютерного зрения, а также обработки изображений и численных алгоритмов OpenCV. Это реализовано на большинстве современных языков программирования, имеет открытый исходный код. Если говорить про компьютерное зрение, Python использующее в качестве языка программирования, то это также имеет поддержку данной библиотеки, кроме того, она постоянно развивается и имеет большое сообщество.
Компания "Майкрософт" предоставляет свои Api-сервисы, способные обучить нейросети для работы именно с изображениями лиц. Есть возможность применять также компьютерное зрение, Python использующее в качестве языка программирования.
Способность видеть, то есть воспринимать информацию об окружающем мире с помощью органов зрения, - одно из важных свойств человека. Посмотрев на картинку, мы, почти не задумываясь, можем сказать, что на ней изображено. Мы различаем отдельные предметы: дом, дерево или гору. Мы понимаем, какой из предметов находится ближе к нам, а какой - дальше. Мы осознаём, что крыша домика - красная, а листья на дереве - зелёные. Наконец, мы можем с уверенностью заявить, что наша картинка - это пейзаж, а не портрет или натюрморт. Все эти выводы мы делаем за считанные секунды.
Компьютеры справляются со многими задачами гораздо лучше, чем человек. Например, они гораздо быстрей считают. Однако такое, казалось бы, несложное задание, как найти на картинке дом или гору, может поставить машину в тупик. Почему так происходит?
Человек учится распознавать - то есть находить и отличать от других - объекты всю жизнь. Он видел дома, деревья и горы бессчётное количество раз: как в действительности, так и на картинах, фотографиях и в кино. Он помнит, как выглядят те или иные предметы в разных ракурсах и при разном освещении.
Машины создавались для того, чтобы работать с числами. Необходимость наделить их зрением возникла относительно недавно. Распознавание номерных знаков автомобилей, чтение штрихкодов на товарах в супермаркете, анализ записей с камер наблюдения, поиск лиц на фото, создание роботов, умеющих находить (и обходить) препятствия, - всё это задачи, которые требуют от компьютера способности «видеть» и интерпретировать увиденное. Набор методов, позволяющих обучить машину извлекать информацию из изображения - будь то картинка или видеозапись, - называется компьютерным зрением.
Как учится компьютер
Чтобы компьютер находил на изображениях, скажем, домики, нужно его этому научить. Для этого необходимо составить обучающую выборку. В нашем случае это будет коллекция картинок. Она, во-первых, должна быть достаточно большой (невозможно научить чему-то на двух-трёх примерах), во-вторых - репрезентативной (необходимо, чтобы она отражала природу данных, с которыми мы работаем), а в-третьих, должна содержать как положительные («на этой картинке есть домик»), так и отрицательные («на этой картинке нет домика») примеры.

После того как мы составили выборку, в дело вступает машинное обучение. В ходе обучения компьютер анализирует изображения из выборки, определяет, какие признаки и комбинации признаков указывают на то, что на картинке - домик, и просчитывает их значимость. Если обучение прошло успешно (чтобы удостовериться в этом, проводятся проверки), то машина может применять полученные знания «на практике» - то есть находить домики на любых картинках.
Анализ изображения
Человеку ничего не стоит выделить на картинке важное и неважное. Компьютеру это сделать гораздо сложнее. В отличие от человека, он оперирует не образами, а числами. Для компьютера изображение - это набор пикселей, у каждого из которых есть своё значение яркости или цвета. Чтобы машина смогла получить представление о содержимом картинки, изображение обрабатывают с помощью специальных алгоритмов.
Сначала на картинке выявляют потенциально значимые места - то есть предполагаемые объекты или их границы. Это можно сделать несколькими способами. Рассмотрим, к примеру, алгоритм Difference of Gaussians (DoG, разность гауссиан). Он подразумевает, что исходную картинку несколько раз подвергают размытию по Гауссу, каждый раз используя разный радиус размытия. Затем результаты сравнивают друг с другом. Этот способ позволяет выявить на изображении наиболее контрастные фрагменты - к примеру, яркие пятна или изломы линий.
После того как значимые места найдены, их описывают в числах. Запись фрагмента картинки в числовом виде называется дескриптором. С помощью дескрипторов можно быстро, полно и точно сравнить фрагменты изображения, не используя сами фрагменты. Существуют разные алгоритмы получения дескрипторов - например, SIFT , SURF , HOG и многие другие.
Поскольку дескриптор - это числовое описание данных, то сравнение изображений - одна из важнейших задач в компьютерном зрении - сводится к сравнению чисел. Дескрипторы выражены довольно большими числами, поэтому их сравнение может требовать заметных вычислительных ресурсов. Чтобы ускорить вычисления, дескрипторы распределяют по группам, или кластерам. В один и тот же кластер попадают похожие дескрипторы с разных изображений. Операция распределения дескрипторов по кластерам называется кластеризацией.
После кластеризации данный дескриптор изображения сам по себе можно не рассматривать; важным становится лишь номер кластера с дескрипторами, наиболее похожими на данный. Переход от дескриптора к номеру кластера называется квантованием, а сам номер кластера - квантованным дескриптором. Квантование существенно сокращает объём данных, которые нужно обработать компьютеру.
Опираясь на квантованные дескрипторы, компьютер выполняет такие задачи, как распознавание объектов и сравнение изображений. В случае с распознаванием квантованные дескрипторы используются для обучения классификатора - алгоритма, который отделяет изображения «с домиком» от изображений «без домика». В случае со сравнением картинок компьютер сопоставляет наборы квантованных дескрипторов с разных изображений и делает вывод о том, насколько похожи эти изображения или их отдельные фрагменты. Такое сравнение лежит в основе поиска дубликатов и .
Это лишь один подход к анализу изображения, поясняющий, как компьютер «видит» предметы. Существуют и другие подходы. Так, для распознавания изображений всё чаще применяются нейронные сети . Они позволяют выводить важные для классификации признаки изображения непосредственно в процессе обучения. Свои методы работы с изображением используются и в узких, специфических областях - например, при чтении штрихкодов.
Где используется компьютерное зрение
В умении распознавать человек, однако, пока оставляет компьютер далеко позади. Машина преуспела лишь в определённых задачах - например, в распознавании номеров или машинописного текста. Успешно распознавать разнородные объекты и произвольные сцены (разумеется, в условиях реальной жизни, а не лаборатории) компьютеру всё ещё очень трудно. Поэтому когда мы вводим в поисковую строку в Яндекс.Картинках слова «карбюратор» или «танцующие дети», система анализирует не сами изображения, а преимущественно текст, который их сопровождает.
Тем не менее, в ряде случаев компьютерное зрение может выступать серьёзным подспорьем. Один из таких случаев - это работа с лицами. Рассмотрим две связанные друг с другом, но разные по смыслу задачи: детектирование и распознавание.

Часто бывает достаточно просто найти (то есть детектировать) лицо на фотографии, не определяя, кому оно принадлежит. Так работает фильтр « » в Яндекс.Картинках. Например, по запросу [формула-1] будут найдены главным образом фотографии гоночных болидов. Если же уточнить, что нас интересуют лица, Яндекс.Картинки покажут фотографии гонщиков.
В иных ситуациях нужно не только отыскать лицо, но и узнать по нему человека («Это - Вася»). Такая функция есть в Яндекс.Фотках. При распознавании система берёт за образец уже размеченные фотографии с человеком, поэтому область поиска сильно сужается. Имея десять фотографий, на которых уже отмечен Вася, узнать его на одиннадцатом снимке будет несложно. Если Вася не хочет, чтобы его знали в лицо, он может запретить отмечать себя на фото.
Одна из самых перспективных сфер применения компьютерного зрения - дополненная реальность. Так называют технологию, которая предусматривает наложение виртуальных элементов (например, текстовых подсказок) на картину реального мира. Примером могут быть, например, мобильные приложения, которые позволяют получить информацию о доме, направив на него камеру телефона или планшета. Дополненная реальность уже применяется в программах, сервисах и устройствах, но пока находится только в начале пути.
Компьютерное зрение и распознавание изображений являются неотъемлемой частью (ИИ), который за прошедшие годы обрел огромную популярность. В январе этого года состоялась выставка CES 2017, где можно было посмотреть на последние достижения в этой сфере. Вот несколько интересных примеров использования компьютерного зрения, которые можно было увидеть на выставке.
8 примеров использования компьютерного зрения
Вероника Елкина1. Беспилотные автомобили
Самые крупные стенды с компьютерным зрением принадлежат автомобильной промышленности. В конце концов, технологии беспилотных и полуавтономных автомобилей работают, во многом, благодаря компьютерному зрению.
Продукты компании NVIDIA, которая уже сделала большие шаги в области глубинного обучения, используются во многих беспилотных автомобилях. Например, суперкомпьютер NVIDIA Drive PX 2 уже служит базовой платформой для беспилотников , Volvo, Audi, BMW и Mercedes-Benz.
Технология искусственного восприятия DriveNet от NVIDIA представляет собой самообучаемое компьютерное зрение, работающее на основе нейронных сетей. С ее помощью лидары, радары, камеры и ультразвуковые датчики способны распознавать окружение, дорожную разметку, транспорт и многое другое.
3. Интерфейсы
Технологии отслеживания движения глаз с помощью компьютерного зрения используется не только в игровых ноутбуках, но и в обычных, и корпоративных компьютерах, для того чтобы ими могли управлять люди, которые не могут воспользоваться руками. Tobii Dynavox PCEye Mini представляет собой устройство размером с шариковую ручку, которое станет идеальным и незаметным аксессуаром для планшетов и ноутбуков. Также эта технология отслеживания движения глаз используется в новых игровых и обычных ноутбуках Asus и смартфонах Huawei.
Тем временем продолжает развиваться жестовое управление (технология компьютерного зрения, которое может распознавать особые движения руками). Теперь оно будет использоваться в будущих автомобилях BMW и Volkswagen.

Новый интерфейс HoloActive Touch позволяет пользователям управлять виртуальными 3D-экранами и нажимать кнопки в пространстве. Можно сказать, что он представляет собой простую версию самого настоящего голографического интерфейса Железного человека (он даже точно так же реагирует легкой вибрацией на нажатие элементов). Благодаря таким технологиям, как ManoMotion , можно будет легко добавить жестовое управление практически в любое устройство. Причем для получения контроля над виртуальным 3D-объектом с помощью жестов ManoMotion использует обычную 2D-камеру, так что вам не понадобится никакое дополнительное оборудование.
Устройство eyeSight’s Singlecue Gen 2 использует компьютерное зрение (распознавание жестов, анализ лица, определение действий) и позволяет управлять с помощью жестов телевизором, «умной» системой освещения и холодильниками.

Hayo
Краудфандинговый проект Hayo , пожалуй, является самым интересным новым интерфейсом. Эта технология позволяет создавать виртуальные средства управления по всему дому - просто подняв или опустив руку, вы можете увеличить или уменьшить громкость музыки, или же включить свет на кухне, взмахнув рукой над столешницей. Все это работает благодаря цилиндрическому устройству, использующему компьютерное зрение, а также встроенную камеру и датчики 3D, инфракрасного излучения и движения.
4. Бытовые приборы
Дорогие камеры , которые показывают, что находится внутри вашего холодильника, уже не кажутся такими революционными. Но что вы скажете о приложении, которое анализирует изображение со встроенной в холодильник камеры и сообщает, когда у вас заканчиваются определенные продукты?

Элегантное устройство FridgeCam от Smarter крепится к стенке холодильника и может определять, когда истекает срок годности, сообщать, что именно находится в холодильнике, и даже рекомендовать рецепты блюд из выбранных продуктов. Устройство продается по неожиданно доступной цене - всего за $100.
5. Цифровые вывески
Компьютерное зрение может изменить то, как выглядят баннеры и реклама в магазинах, музеях, стадионах и развлекательных парках.
На стенде Panasonic была представлена демоверсия технологии проецирования изображения на флаги. С помощью инфракрасных маркеров, невидимых для человеческого глаза, и стабилизации видео, эта технология может проецировать рекламу на висящие баннеры и даже на флаги, развевающиеся на ветру. Причем изображение будет выглядеть так, будто бы оно действительно на них напечатано.
6. Смартфоны и дополненная реальность
Многие говорили об игре как о первом массовом приложении с элементами (AR). Однако как и другие приложения, пытающиеся запрыгнуть на AR-поезд, эта игра больше использовала GPS и триангуляцию, чтобы у пользователей возникло ощущение, что объект находится прямо перед ними. Обычно в смартфонах практически не используются настоящие технологии компьютерного зрения.

Однако в ноябре Lenovo выпустила Phab2 - первый смартфон с поддержкой технологии Google Tango . Эта технология представляет собой комбинацию датчиков и ПО с компьютерным зрением, которая может распознавать изображения, видео и окружающий мир в реальном времени с помощью линзы фотокамеры.

На выставке CES Asus впервые представила ZenPhone AR - смартфон с поддержкой Tango и Daydream VR от Google. Смартфон не только может отслеживать движения, анализировать окружение и точно определять положение, но и использует процессор Qualcomm Snapdragon 821, который позволяет распределять загрузку данных компьютерного зрения. Все это помогает применять настоящие технологии дополненной реальности, которые на самом деле анализируют обстановку через камеру смартфона.
Позже в этом году выйдет Changhong H2 - первый смартфон со встроенным молекулярным сканером. Он собирает свет, который отражается от объекта и разбивается на спектр, и затем анализирует его химический состав. Благодаря программному обеспечению, использующему компьютерное зрение, полученная информация может использоваться для разных целей - от выписки лекарств и подсчета калорий до определения состояния кожи и расчета уровня упитанности.
| 15 сентября в Москве состоится конференция по большим данным Big Data Conference . В программе - бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. Следите за Big Data Conference в |